Insights
Read our latest reports, articles and case studies covering five pillars of AI capability.
Explore all insights →Insights
Read our latest reports, articles and case studies covering five pillars of AI capability.
Explore all insights →

Data-driven insights and news
on how banks are adopting AI

6 February 2025
Agentic AI startup Auquan is aiming to change what it means to be an analyst, and UBS (among other banks) is buying in.
What OpenAI’s newly-released “Deep Research” agent does for general reports, Auquan’s system is doing specifically for finance. It cleans messy data (like presentations and PDFs) and proposes a list of relevant questions to address – and then dispatches a swarm of agents to scour internal documents and the wider internet to answer them in a report.
In an interview, CEO Chandini Jain told Evident data scientist Alex Inch that clients are clamoring for solutions that address the inconsistency issues of LLMs, and that while AI agents can’t yet handle the workload of a graduate-level analyst, they soon will.
INCH: Can I ask quickly about the pipeline? Are you saying you're using agents to automate the different steps of building a RAG pipeline into a document generation output, where you have agents which are taking unstructured data to structured data?
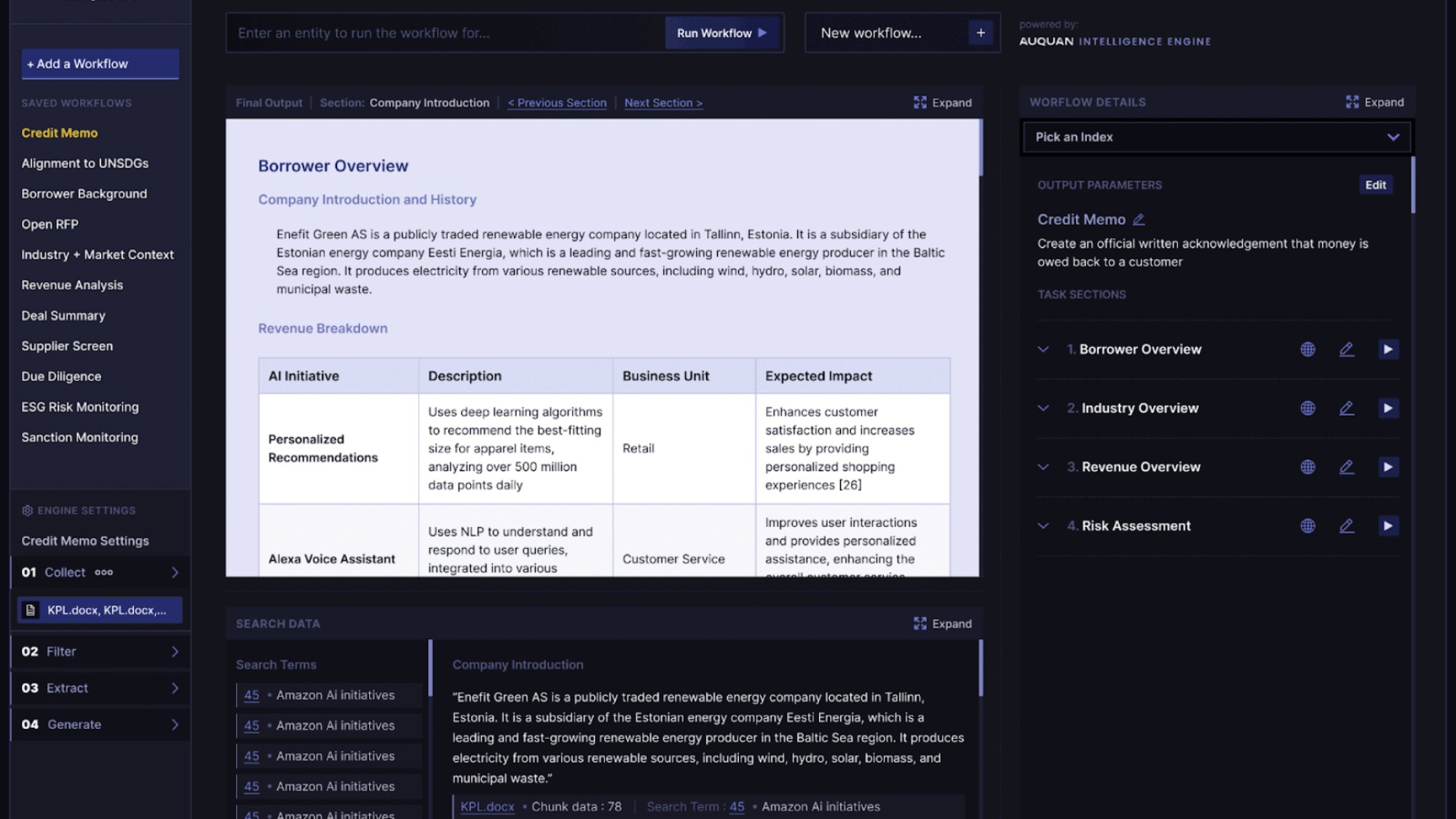
JAIN: We think of this basically as we're a system of action. So there is a lot of work being done on AI for enterprise productivity, AI for knowledge workers, but a lot of those are systems of research. They connect to internal and external data, they search and find information, but you still have to go on and do the rest of the work yourself. We think you can drive real value in enterprise if you completely eliminate entire jobs to be done. So if you look at these people, day to day, week to week, and you say, okay, in the life of an analyst and investment bank, these are the 20 jobs to be done in a week. And of these 20 jobs to be done, these five jobs to be done like writing a compliance report, writing the competitive section, and I see memo writing a risk report. These can fully be eliminated using AI. Upload a document, select a company, press a button, and the report just gets generated. That document generation is a big difference, but it's not a system of research. We completely automate and eliminate that job to be done. We think of it not as workflow assistance, but workflow completion.
For these tasks, off the shelf LLMs today will not work. Let's say you have ChatGPT Enterprise. If you give it a few PDFs and ask simple questions like “what does this company do” you will get good answers. But once your dataset becomes large, thousands to hundreds of thousands of documents of all kinds your tasks also become complex, and that’s when off the shelf LLMs start to fail and give you generic answers. You need something sitting in between the documents and the LLM. That is one, processing all of the data, cleaning it down to the data points that actually contain relevant information and filtering out everything else. Second, you need something that understands the intent of your task and breaks it down into the right tasks that the LLM can actually operate on. So you need an agent orchestrator that is sitting in between, and that’s a truly agentic workflow: something that is automatically figuring out what needs to be done, and then sending it to the right places to do that. And this orchestrator that sits in between also needs to be domain specific. It needs to understand your workflow, if it is risk or compliance or due diligence or something else, and ideally, it also understands your firm, so it can generate documents that look like they have been made by others inside your organization, in your format, in your colors, in your template.
Source: Auquan
When you talk about domain specificity, is that being achieved by fine tuning?
It's coming out of two things. One is fine-tuning that we've built into the platform. So the system understands what EBIDTA means, and it also understands what the underlying components of EBITDA are, so it could find those elements and run code to calculate it if they’re missing from a document. On top of that, the workflow understanding comes from how the agent is orchestrating the task. First the users give us the input data that they want to use, and they give us an output template. The system parses the template to figure out the tasks it needs to complete. What are the sections, what are the sub-sections, what are the individual questions that need answering, and what should the system search for to answer those questions. We then stitch all that up into a final document, and this customer-driven workflow gives us more of that domain specificity.
Once that is done we show it to the customer to cue if they want to make any changes. That’s all based on RAG. We're running individual searches, but before we run those searches, we're breaking the larger task down into smaller tasks. Then we support web-search and pulling data ourselves—we’re connected to over 2 million data sources publicly. We also connect to our customers’ external data vendors and connect to them. And lastly we connect to internal data, in their SharePoint or local databases. Once you put all of this information in, we run a lot of pre- processing the contents of these data files: you want to treat a PDF differently to an Excel file; a presentation with charts differently to a presentation with numbers or tables; a transcript of an expert network call differently to an earnings call. We chunk that data page by page, understand the contents of the page, extract entities, people and topics mentioned, whether it contains financial reporting or not, extract information out from images and a lot of other pre-processing. All of that metadata is then stored in a vector database, which gives us very clean search results. For RAG pipelines, it's junk data in, junk answers out.
When you’re thinking about data cleaning versus the agentic LLM answering, is there a relative importance there or are they equally important?
It's 50/50. If you didn't have the pre-processing, even if we did very clever things on the 2nd step, your search results would just be noisy, and you'd get noisy results. And on the opposite side, if, even if we had very good data, if you're not running the right search terms and you hadn't broken down the task in the right manner, then you just wouldn't get the right result. So I think that it's 50/50.
How long has it taken you to tweak your approach to the point of deployment?
There's been a lot of internal development in the last year, but we also predate LLMs as a company. So a lot of the work, at least on data pre-processing, was done pre-LLMs. So in our pipeline of RAG (Retrieval-Augmented Generation - fetching useful data to make LLM answers more relevant) the retrieval came first. For lots of people generation came first, and then they realized that the AI was generating junk without good data. I think AI is 80% product, 20% customization.
At this point Jain launches into a demo. She shows me Auquan’s platform, uploads a few folders with various messy documents, and asks the system to use them to generate a credit memo. The system spins up a plan of action for the user to review, including a list of sections to be written: overview, company management, key geographies and offices, each with their own further editable plans. It also generates a list of over 70 planned searches across uploaded documents and other data sources. It would be familiar to users of Google’s Deep Research agent, but with significantly more control over the plan and data sources. Jain tells me that most users of the product are juniors, analysts using it to write reports more quickly than they would otherwise be able. When the document is completed, it comes with citations that link back to the source documents, something Jain tells me is critical for allaying customer concerns about validity.
"20 years ago being an analyst in a bank meant that if you gave a presentation you had to print it out, cut it to shape and bind it together. No one does that today, but that doesn't mean you don't need analysts."
- Chandini Jain
The reliability of LLMs can be a concern with agentic systems, how have you managed it?
We have 3 criteria. Our system should be comprehensive, noise-free and consistent. First we have the LLM generate loads of search terms (in the demo I saw well over 70+), so we can say with very high certainty the outputs that we get are comprehensive. That was a big question for our customers. Second, we keep it noise-free by understanding the domain and filtering irrelevant information out of those searches. And thirdly we aim for consistency: if you run the same thing 5 times you will get similar results. That’s a big challenge our customers have faced with ChatGPT - the same question 5 times will yield 5 different results. And the last thing is the use of search. Everything is always backed by data from the underlying real-world sources, so if you’re unsure of something you can always trace it back to the source via a citation.
Have you experimented with different models? Do you try to integrate new models as they come out, or have you settled on a specific workflow?
No one should lock themselves into a model, because the model performances are changing constantly. We started with GPT-3.5, but now we’re using 4o-mini for lots of things under the hood. And then 4o is quite expensive, so we use an internal, hosted version of Llama, for some of the internal facing stuff—it does quite a lot of pre-processing. And then the new Claude model is actually quite good at some image tasks as well. So it's multi-model. Having said that, if a customer has a preference, for example, if they’re an Azure customer as well, we can support Azure OpenAI.
With rising AI interest we’re also seeing concerns in business about cost. Models are getting cheaper, but the smartest models are still expensive. Is cost a concern? How do you manage it? How much do you charge to generate a report?
Cost is definitely a concern, and I think it is possible to keep costs in control. If you use the best model for everything you would theoretically get the best performance, but that’s using a big hammer for a very small nail. So the way we’re keeping costs low is use the most cost-optimized model at each step which can do the job. If you can do it with an internal, hosted Llama, use that. As far as pricing there is a big debate over continuing to use a seat-based model or doing usage- or outcome-based models. I think everyone's experimenting. We are outcome-based right now. So we’d say around $500-$1000 dollars for a document, which we estimate is 80-90% cheaper than a human-generated report. How we come up with the pricing is a mix of how much input data needs to be processed, how much further processing is required, and how large the output is.
When you're experimenting with your approach, do you have an internal evaluation set? How do you make sure you're retaining performance while you tweak things?
Yes we have an internal valuation set up. First we have a golden data set for some workflows. So if we make a tweak, we can see if it actually improves performance on the golden dataset. The second is reflection, which is becoming quite popular. That is, you get the LLM to critique its own work. With so many new models and techniques coming out all the time, it's becoming more and more critical.
I know we've gone deep into the weeds, so it could be nice to round things off with some broader questions. For many large banks, they see a lot of innovation happening at startups, but can have difficulties interfacing with a small team. There might be questions about where a startup can support a bank in every jurisdiction, and handle all of the compliance requests that need to be made. Have you and your larger partners found any difficulties that you've had to overcome to work together?
Yes and no. I think it’s the cost of doing business with large enterprise, right? So we work with UBS and MetLife. A year into it, it's gotten easier. Early on there were a lot of compliance and data protection requirements. And also internal access management: one team's data should not be visible to another team. But those things are built into the platform. One of the pitches that we make to customers is that a horizontal, general purpose platform will not understand the domain. Last month they might have worked on a marketing campaign, this month they will work with you, and next month they might work on a sales campaign for a pharma company. So they might not understand compliance requirements, where you are and are not allowed to host your data, what you mean when you say you have a Chinese wall. I can see why it is a challenge for banks to work with startups, but I think you need to work with someone who is very domain-specific to you, because then those challenges are basic requirements for them.
You mentioned that you've been active in machine learning now for nearly eight years. What are your broader thoughts on the rise of generative AI?
It’ll change loads. Our team has been dealt a very good hand in the last year, since it's opened up people's willingness to experiment and try. Everyone acts like AI was born two years ago, but that's not the case. We've been doing lots of things with AI even before that, but I think it's just captured people's interest in a manner that wasn't possible before—it almost seems magical, right? Outside of that, the ROI statement has changed quite significantly for us. Previously, because we did not have the capability to generate new content, the best experience we could offer on our platform was to connect to all of your data. It would rank it, but you would still have to go read it. Now with generation, I'm saying you don't even have to go read those documents. I will generate the entire report for you. So that has significantly changed the ROI statement for the customers and how much work we can take off their hands. One other is just that we put so much effort into building things in 2021 and 2022 which are now two-line prompts to an LLM. You obviously need the domain specific bit, but extracting entities, for example, is much, much simpler than it used to be. So I think as an enabling technology, it’s changed the underlying tech stack quite significantly, but mostly what the biggest shift has been in terms of awareness in the market and people's propensity to buy, and also the ROI we're able to offer to them.
If you’re researching and generating, you're beginning to complete the full agentic loop. Do you consider what you’re doing agentic AI?
What we're doing is basically the agent architecture. Anthropic wrote a post in December that explains it well. So there's the traditional workflow, which is a predefined code path to say step one, step two, step three, step four… That’s what RPA used to be, and we've had that for a very long time. Then you had LLM calls, which are fuzzy. It is still a predefined code path to step one, step two and so on, but the LLM can deal with fuzziness. Before you had to say “go into this folder, open a file which has this name, and on page number five in this table, extract this value”. With LLMs you can say, “go find this value, it’s in one of the files in one of these folders.” With agentic, it's not even a predefined code path. You're not saying, step one, step two and so on, you're saying “complete this task”, and the agent can itself figure the right steps? That’s when you start to get truly agentic. I think we're halfway there in terms of what is possible in the world, you need to give an agent some sort of starting point. In our case, for example, you need to give an output format to explain what a compliance report is. From there, it can figure out its path itself eventually. The hope is, once the system sees enough of these checklists or work plans, it can start to generate new plans entirely on its own.
Lots of people are talking about their agentic AI solutions. Do you think they're actually doing truly agentic AI?
I think in 2023 when people were saying they were “doing LLMs”, it was mostly likely pre-defined codepaths with some sort of LLM chatbot functionality built in. Then 2024 went more into more genuine uses of LLMs. I do think a lot of people are passing that off as agentic, but I also think we'll start to see movement into true agentic. The difference between an AI agent and an analyst today is you can give an analyst any output and they can think through it and produce that. Versus what we're calling AI agents can think through some tasks but not others. But I think you will get to a point where they're able to think through as many tasks as a graduate level analyst, and that is when you can say agents will enter the workforce. So I don't think it's there yet. When people are saying agentic, they're working towards agentic, including us.
Okay, my last few questions. First, what do you think AI will change, and what do you think it won't change?
I think it will hugely change the nature of work, for sure. We think of this almost like an industrial revolution. We used to do a lot of physical work manually, and then production lines came and a lot of that physical work went into production. And people just don’t do that work any more, but that doesn’t mean that people had less things to do. Now we just focus on more important things, and it boosted the overall capacity of human brains, right? How much productivity we could get out of ourselves is a hugely interesting paradigm shift. I think what we’re seeing right now is quite similar in terms of that work that we used to do in the past. A lot of that will go away, and the scale at which that work can happen will completely change. So I think AI will change that. What it won’t change is that people continue to focus on the creative bits, the bits that actually require human thinking. We just need to see a lot more of that happen. So in my head, it's almost like there is no difference between what is happening now in the digital world compared to what happened during the Industrial Revolution in the physical world.
Do you have any thoughts on the more nuanced effects of GenAI on work? In some sense, is Auquan aiming to eliminate the role of analyst?
It is eliminating a lot of the work that analysts do today, but I don't think it is eliminating the analyst role in a bank. 20 years ago being an analyst in a bank meant that if you gave a presentation you had to print it out, cut it to shape and bind it together. No one does that today, but that doesn't mean you don't need analysts. I think a more subtle effect I already see is that, just as you manage analysts, you will have to manage AI agents and AI workers. You can't escape from technology and choose not to become AI-aware. If everybody at JP Morgan is getting work done using AI, and you're still doing it manually you will just produce a lot less. So you will have to get AI to do your work for you, and you'll have to learn to manage AI.